Datenerhebung für die Analyse
Dieser Artikel beschreibt die grundlegenden Schritte der Datenerhebung, die eingehalten werden können, um die richtige Menge an qualitativen Daten für die Analyse zu erhalten. Die Methodik ist kein striktes Regelwerk, sondern eine Liste von Empfehlungen, die befolgt werden sollten.
Beim Data Mining werden Algorithmen des maschinellen Lernens eingesetzt, um die Entwicklung der Situation vorherzusagen, Muster zu erkennen, die Bedeutung von Faktoren zu bewerten usw.
Es gibt viele solcher Algorithmen, aber selbst die leistungsfähigsten können kein gutes Ergebnis garantieren. Algorithmen für maschinelles Lernen können nur dann Muster in Daten finden, wenn die Informationen korrekt erfasst wurden. In der Praxis sind es meist Datenprobleme, die die Ursache für Misserfolge sind.
Im Folgenden werden die Schritte der Datenerfassung beschrieben, nach denen Sie qualitativ hochwertige Daten in der richtigen Menge für die Analyse vorbereiten können. Die vorgeschlagene Methodik ist einfach und logisch, aber unerfahrene Analysten machen fast immer die gleichen trivialen Fehler. Wenn Sie die beschriebenen Regeln befolgen, erhöht sich die Wahrscheinlichkeit, dass Sie hochwertige Ergebnisse erhalten. Bei diesen Methoden handelt es sich nicht um ein starres Regelwerk, sondern um eine Liste von Empfehlungen, die zu befolgen ist.
Das allgemeine Schema für die Anwendung von Data-Mining-Algorithmen besteht aus den folgenden Schritten:
-
Formulierung der Hypothese
-
Sammeln und Organisieren von Daten
-
Auswahl eines Modells zur Erklärung der gesammelten Daten
-
Prüfung und Auswertung der Ergebnisse
-
Verwendung des Modells
Es ist jedoch möglich, in jeder Stufe einen oder mehrere Schritte zurückzugehen.
Dieser Ablauf ist domänenunabhängig und kann daher für einen beliebigen Bereich verwendet werden.
Hypothesen aufstellen
Eine Hypothese ist eine Vermutung über den Einfluss bestimmter Faktoren auf den untersuchten Prozess. Die Form der Beziehung spielt keine Rolle. Das heißt, man kann bei der Aufstellung einer Hypothese zum Beispiel sagen, dass der Absatz durch die Abweichung des Produktpreises vom Marktdurchschnitt beeinflusst wird, aber nicht angeben, wie genau dieser Faktor den Absatz beeinflusst. Mit Hilfe des maschinellen Lernens werden Form und Ausmaß der Abhängigkeiten ermittelt.
Es ist nicht möglich, den Prozess der Hypothesenbildung zu automatisieren, zumindest nicht beim derzeitigen Stand der Technik. Diese Aufgabe muss von Experten erledigt werden. Es ist möglich und notwendig, sich auf ihre Erfahrung und ihren Sachverstand zu verlassen. Es ist notwendig, ihr Wissen über das Thema optimal zu nutzen und so viele Hypothesen/Annahmen wie möglich zu sammeln.
Eine gute Taktik hierfür ist das Brainstorming, bei dem alle Ideen gesammelt und systematisiert werden, ohne dass versucht wird, ihre Angemessenheit zu bewerten. Das Ergebnis dieses Schrittes sollte eine Liste aller von den Experten vorgeschlagenen Faktoren sein.
Für die Aufgabe der Nachfrageprognose könnte es sich beispielsweise um eine Liste der folgenden Punkte handeln: Jahreszeit, Wochentag, Verkaufsvolumen der vorangegangenen Wochen, Verkaufsvolumen im gleichen Zeitraum des letzten Jahres, Werbekampagne, Marketingaktivitäten, Produktqualität, Marke, Preisabweichung vom Marktdurchschnitt, Verfügbarkeit von Waren der Wettbewerber.
Bei der Auswahl der Einflussfaktoren ist es notwendig, von bestehenden Informationssystemen und verfügbaren Daten zu abstrahieren. Sehr oft wollen Analysten Daten aus bestehenden Buchhaltungssystemen als Ausgangspunkt nehmen. Das klingt in etwa so: "Wir haben diese und jene Daten: Was lässt sich daraus ableiten?".
Dies scheint auf den ersten Blick logisch, ist aber eine schlechte Praxis. Die Analyse sollte sich auf die jeweilige Aufgabe stützen, und die Daten sollten auf diese Aufgabe zugeschnitten sein, anstatt die verfügbaren Informationen zu nehmen und zu überlegen, was man daraus "herausholen" kann. Man sollte bedenken, dass Buchhaltungssysteme Informationen sammeln, die für ihre Aufgaben notwendig sind, z.B. ist das, was für die Bilanz wichtig ist, für die Aufgabe der Kundensegmentierung bedeutungslos.
Nach der Erstellung einer Tabelle, in der die Faktoren beschrieben werden, ist es notwendig, die Bedeutung der einzelnen Faktoren fachkundig zu bewerten. Diese Bewertung ist nicht endgültig - sie gilt als Ausgangspunkt. Im Laufe der Analyse kann sich herausstellen, dass ein Faktor, den die Experten für wichtig hielten, es nicht ist, und dass umgekehrt ein Attribut, das sie nicht für wichtig halten, einen erheblichen Einfluss hat.
In den meisten Fällen ist die Zahl der Hypothesen groß, so dass es nicht möglich ist, alle Daten zu sammeln und zu analysieren. Es muss eine einigermaßen begrenzte Liste von Faktoren zugrunde gelegt werden. Am einfachsten ist es, sich auf das Urteil von Experten über die Bedeutung der Attribute zu verlassen. Dies gilt umso mehr, als die tatsächlichen Daten häufig ihre Meinung bestätigen.
Das Ergebnis dieses Schrittes könnte eine Tabelle der folgenden Form sein:
| Indikator | Experteneinschätzung der Bedeutung (1-100) |
|---|---|
| Saison | 100 |
| Wochentag | 80 |
| Verkäufe der letzten Wochen | 100 |
| Verkaufsvolumen für den gleichen Zeitraum des Vorjahres | 95 |
| Werbekampagne | 60 |
| Marketingaktivitäten | 40 |
| Produktqualität | 50 |
| Marke | 25 |
| Preisabweichung vom durchschnittlichen Marktpreis | 60 |
| Verfügbarkeit dieses Produkts bei Wettbewerbern | 15 |
Formalisierung und Datenerhebung
Im nächsten Schritt wird festgelegt, wie die Daten dargestellt werden, indem einer der 4 Typen ausgewählt wird: - Zahl, String, Datum, logische Variable (ja/nein).
Einige Daten sind recht einfach zu formalisieren, d.h. die Art der Darstellung zu definieren. Zum Beispiel ist der Umsatz in Euro eine Zahl. Es gibt jedoch häufig Situationen, in denen nicht klar ist, wie ein Faktor dargestellt werden soll.
Am häufigsten treten solche Probleme bei qualitativen Merkmalen auf. So werden beispielsweise die Verkaufsmengen durch die Qualität des Produkts beeinflusst, aber dies ist ein recht komplexes Konzept, bei dem nicht klar ist, wie es dargestellt werden kann. Wenn dieses Attribut jedoch wirklich wichtig ist, müssen Sie sich überlegen, wie Sie es formalisieren können. Definieren Sie die Qualität beispielsweise durch die Anzahl der Fehler pro tausend Einheiten oder durch ein Expertenurteil, indem Sie sie in mehrere Kategorien einteilen - schlecht/befriedigend/gut/ausgezeichnet.
Als nächstes müssen die Kosten für die Erhebung der für die Analyse erforderlichen Daten geschätzt werden. Einige Daten sind leicht verfügbar, z. B. können sie aus bestehenden Informationssystemen heruntergeladen werden. Es gibt jedoch Informationen, die nur schwer zu erheben sind, wie z. B. Informationen über die Verfügbarkeit von Produkten der Wettbewerber. Daher müssen Sie abschätzen, wie viel die Erhebung der Daten kosten wird.
Je mehr Daten Sie zu analysieren haben, desto besser. Es ist einfacher, sie zu einem späteren Zeitpunkt zu verwerfen, als neue Informationen zu sammeln. Außerdem sollten Sie bedenken, dass die Beurteilung der Bedeutung von Faktoren durch Experten nicht immer mit der Realität übereinstimmt, d. h. Sie wissen zu Beginn nicht, was tatsächlich wichtig ist und was nicht. Aufgrund der großen Unsicherheit muss man sich auf die Meinung von Experten über die Bedeutung von Faktoren verlassen, aber in der Realität können diese Hypothesen nicht bestätigt werden. Daher ist es wünschenswert, mehr Daten zu sammeln, um die Auswirkungen möglichst vieler Indikatoren bewerten zu können.
Die Datenerhebung ist jedoch kein Selbstzweck. Wenn Informationen leicht zu beschaffen sind, dann müssen sie natürlich auch gesammelt werden. Wenn die Daten schwer zu beschaffen sind, müssen die Kosten für ihre Erhebung und Systematisierung gegen die erwarteten Ergebnisse abgewogen werden.
Es gibt verschiedene Methoden, um die Daten zu sammeln, die Sie für Ihre Analyse benötigen. Sie sind in der Reihenfolge der steigenden Kosten aufgeführt:
-
Export aus den Buchhaltungssystemen. In der Regel verfügen Buchhaltungssysteme über Mechanismen für den Datenexport oder es gibt eine API für den Zugriff auf diese Daten. Daher ist die Extraktion der benötigten Informationen aus den Buchhaltungssystemen in der Regel ein relativ einfacher Vorgang.
-
Gewinnung von Informationen aus indirekten Daten. Viele Indikatoren lassen sich aus indirekten Faktoren ableiten. So ist es beispielsweise möglich, die tatsächliche finanzielle Situation der Einwohner einer bestimmten Region einzuschätzen. In den meisten Fällen gibt es mehrere Produkte, die dieselbe Funktion erfüllen, sich aber im Preis unterscheiden: Produkte für die Einkommensschwachen, für die mittlere Einkommensgruppe und für die Wohlhabenden. Liegen Daten über die Verkäufe pro Region vor, so kann analysiert werden, in welchem Verhältnis die Waren für die einzelnen Kundenkategorien verkauft werden: Je höher der Anteil der teuren Produkte, desto wohlhabender ist die durchschnittliche Person in der Region.
-
Nutzung offener Quellen. Viele Daten sind in offenen Quellen verfügbar, z. B. in statistischen Zusammenstellungen, Unternehmensberichten, veröffentlichten Ergebnissen der Marktforschung usw.
-
Kauf von Daten von sozialen Netzwerken, Mobilfunkbetreibern und Datenmaklern. Auf dem Markt gibt es viele Unternehmen, die Daten sammeln und verkaufen. Sie stellen systematisierte Informationen über API bereit: Kreditwürdigkeit, Kundenpräferenzen, Produktpreise, Geolokalisierung usw.
-
Durchführung eigener Marktforschung und ähnlicher Datenerhebungsaktivitäten. Dies kann recht kostspielig sein, aber in jedem Fall ist diese Option der Datenerhebung möglich.
-
Manuelle Dateneingabe, bei der die Daten auf der Grundlage verschiedener Arten von Expertenurteilen durch die Mitarbeiter der Organisation eingegeben werden. Diese Methode ist arbeitsintensiv und erfordert ständige Ressourcen, um die Aktualität der Daten zu gewährleisten.
Der Aufwand für das Sammeln von Informationen mit verschiedenen Methoden ist sehr unterschiedlich, was sowohl die Kosten als auch die benötigte Zeit betrifft. Die Kosten sollten daher gegen die erwarteten Ergebnisse abgewogen werden. Einige Datenerhebungen müssen möglicherweise aufgegeben werden, aber die Faktoren, die die Experten als die wichtigsten identifiziert haben, sollten unabhängig von den Kosten der Arbeit erhoben werden, oder die Analyse sollte ganz aufgegeben werden.
Wenn ein Experte einen Faktor als wichtig eingestuft hat, ist es natürlich nicht sinnvoll, ihn auszuschließen. Es besteht die Gefahr, dass man sich bei der Analyse auf sekundäre, unwichtige Faktoren konzentriert und so ein Modell erhält, das schlechte und instabile Ergebnisse liefert. Ein solches Modell ist von keinem praktischen Wert.
Die gesammelten Daten müssen in ein gemeinsames Format konvertiert werden. Im Idealfall werden sie in eine Datenbank oder ein Data Warehouse geladen. Aber auch einfachere Formate, wie Excel oder eine Textdatei mit Trennzeichen, können verwendet werden.
Die Daten müssen immer standardisiert sein, d.h. die gleichen Informationen müssen überall auf die gleiche Weise beschrieben werden. In der Regel treten Probleme mit einer einheitlichen Darstellung auf, wenn Informationen aus heterogenen Quellen gesammelt werden. In diesem Fall ist die Normung eine große Herausforderung für sich selbst, die jedoch den Rahmen dieses Artikels sprengen würde.
Repräsentation und Mindestmengen
Damit Prozesse unterschiedlicher Art analysiert werden können, müssen die Daten in besonderer Weise aufbereitet werden. Der Einfachheit halber kann man davon ausgehen, dass es drei Arten von Daten gibt, die gesammelt werden können:
- Geordnete Daten
- Ungeordnete Daten
- Transaktionsdaten
Geordnete Daten
Geordnete Daten werden für Prognoseaufgaben benötigt, bei denen auf der Grundlage verfügbarer historischer Informationen bestimmt werden muss, wie sich ein Prozess in der Zukunft voraussichtlich verhalten wird. Eines der gebräuchlichsten Attribute ist das Datum oder die Uhrzeit, obwohl dies nicht unbedingt der Fall sein muss. Es kann sich auch um eine Art Referenz handeln, z. B. um Daten, die von Sensoren über eine bestimmte Entfernung gesammelt wurden.
Bei geordneten Daten (in der Regel eine Zeitreihe) entspricht jede Spalte einem Faktor, und jede Zeile enthält zeitlich geordnete Ereignisse mit einem einzigen Intervall zwischen den Zeilen. Die Abstände zwischen den Zeilen müssen gleich sein, und es dürfen keine Lücken entstehen. Darüber hinaus müssen Gruppierungen, Zwischensummen usw. ausgeschlossen werden, d. h. es wird eine reguläre Tabelle benötigt.
| Nr. | Datum | Anzahl der Bestellungen | Umsatz (EUR) |
|---|---|---|---|
| 1 | 2022-05-01 | 256 | 6930,40 |
| 2 | 2022-05-02 | 278 | 7223,95 |
Wenn der Prozess durch Saisonalität/Zyklizität gekennzeichnet ist, müssen Daten für mindestens eine volle Saison/Zyklus vorliegen, wobei die Intervalle variieren können (wöchentlich, monatlich...). Da die Zyklizität komplex sein kann, z. B. vierteljährlich innerhalb eines Jahreszyklus und wöchentlich innerhalb von Quartalen, ist es erforderlich, über vollständige Daten für mindestens einen längeren Zyklus zu verfügen.
Der maximale Vorhersagehorizont hängt von der Menge der Daten ab:
- 1,5-Jahres-Daten - Prognose für maximal 1 Monat;
- Daten für 2-3 Jahre - Prognose für maximal 2 Monate;
Damit wird die minimale Tiefe (Historie) für den jeweiligen Prognosehorizont angegeben, d.h. die Zeit, für die einigermaßen zuverlässige Prognosen gemacht werden können. Ohne mindestens diese Datenmenge ist eine datengestützte Prognose nicht möglich. Es sollte berücksichtigt werden, dass nur die einfachsten Algorithmen mit der angegebenen Mindestdatenmenge funktionieren. Ein komplexer mathematischer Ansatz erfordert mehr Daten, um ein Modell zu erstellen.
Im Allgemeinen wird der maximale Vorhersagehorizont nicht nur durch die Menge der Daten begrenzt. Prognosemodelle gehen davon aus, dass die Faktoren, die die Entwicklung eines Prozesses bestimmen, in der Zukunft ungefähr den gleichen Einfluss haben werden wie jetzt. Diese Annahme ist nicht immer zutreffend. Wenn sich die Situation beispielsweise zu schnell ändert, wenn wichtige neue Faktoren auftauchen usw., funktioniert diese Regel nicht.
Daher können die Anforderungen an die Datenmenge je nach Aufgabe sehr unterschiedlich sein. Es sollte jedoch auch berücksichtigt werden, dass eine zu große Tiefe ebenfalls unangemessen ist. In diesem Fall bauen wir das Modell auf einer alten, irrelevanten Geschichte auf, und daher können Faktoren berücksichtigt werden, die möglicherweise nicht mehr relevant sind.
Ungeordnete Daten
Ungeordnete Daten werden für Aufgaben benötigt, bei denen der Zeitfaktor keine Rolle spielt, wie z. B. Kreditwürdigkeitsprüfung, Diagnose, Kundensegmentierung. In solchen Fällen betrachten wir die Information, dass ein Ereignis vor einem anderen stattgefunden hat, als irrelevant.
Bei ungeordneten Daten entspricht jede Spalte einem Faktor, und jede Zeile enthält ein Beispiel (Situation, Präzedenzfall). Die Zeilen müssen nicht geordnet sein. Es sind keine Gruppierungen, Summen usw. erlaubt - es wird eine normale flache Tabelle benötigt.
| Kunden ID | Dienstalter | Auto | Darlehensbetrag (EUR) |
|---|---|---|---|
| 1 | mehr als 5 Jahre | Ja | 17000 |
| 2 | weniger als 5 Jahre | Nein | 15000 |
In den gesammelten Daten sollte die Anzahl der Beispiele (Präzedenzfälle), d.h. der Tabellenzeilen, deutlich größer sein als die Anzahl der Faktoren, d.h. der Spalten. Andernfalls besteht eine hohe Wahrscheinlichkeit, dass ein Zufallsfaktor das Ergebnis stark beeinflusst. Wenn es keine Möglichkeit gibt, die Zahl der Daten zu erhöhen, muss die Zahl der zu analysierenden Faktoren reduziert werden, wobei die wichtigsten Faktoren übrig bleiben.
Es ist wünschenswert, dass die Daten repräsentativ sind, d. h. möglichst viele Situationen des realen Prozesses abdecken, und dass die Proportionen der verschiedenen Beispiele (Präzedenzfälle) der Realität nahe kommen. Der Zweck des Data Mining besteht darin, Muster in den verfügbaren Daten zu erkennen, und je näher die Daten an der Realität sind, desto besser.
Es muss klar sein, dass Algorithmen für maschinelles Lernen nichts wissen können, was außerhalb der Eingabedaten liegt. Wenn zum Beispiel ein medizinisches Diagnosesystem nur mit Daten über kranke Menschen gefüllt wird, weiß es nicht, dass es auch gesunde Menschen gibt, und daher wird jeder aus seiner Sicht zwangsläufig krank sein.
Transaktionsdaten
Transaktionsdaten werden in Algorithmen für assoziatives Rule Mining verwendet, diese Methode wird oft als "Warenkorbanalyse" bezeichnet. Eine Transaktion bezieht sich auf mehrere Objekte oder Aktionen, die zu einer logisch zusammenhängenden Einheit zusammengefasst sind.
Dieser Mechanismus wird häufig zur Analyse von Einkäufen (Quittungen) in Supermärkten verwendet. Im Allgemeinen können wir über alle zusammenhängenden Objekte oder Handlungen sprechen, wie z. B. den Verkauf von Touristenreisen mit einer Reihe von damit verbundenen Dienstleistungen (Beförderung zum Flughafen, Reiseführer und so weiter). Mit dieser Analysemethode finden wir Abhängigkeiten der Form "wenn Ereignis A eingetreten ist, dann wird mit einer gewissen Wahrscheinlichkeit Ereignis B eintreten".
Die Transaktionsdaten für die Analyse sollten wie folgt aufbereitet werden:
| Transaktioncode | Produkt |
|---|---|
| 10200 | Sahne Joghurt 9% |
| 10200 | Kasseler Brot |
| 10201 | Berliner Landbrot |
| 10201 | Zucker, 1kg |
| 10201 | Mineralwasser, 0,5l |
Der Transaktionscode entspricht der Nummer des Schecks, der Rechnung oder des Lieferscheins. Waren mit demselben Code sind Teil eines einzigen Kaufs.
Die beschriebene Datendarstellung ist ausreichend für die üblichen Assoziationsregeln, bei denen die Verbindungen zwischen den einzelnen Objekten gefunden werden. Zum Beispiel: "Wenn Sie Sahne Joghurt 9% gekauft haben, werden Sie auch Kasseler Brot kaufen.
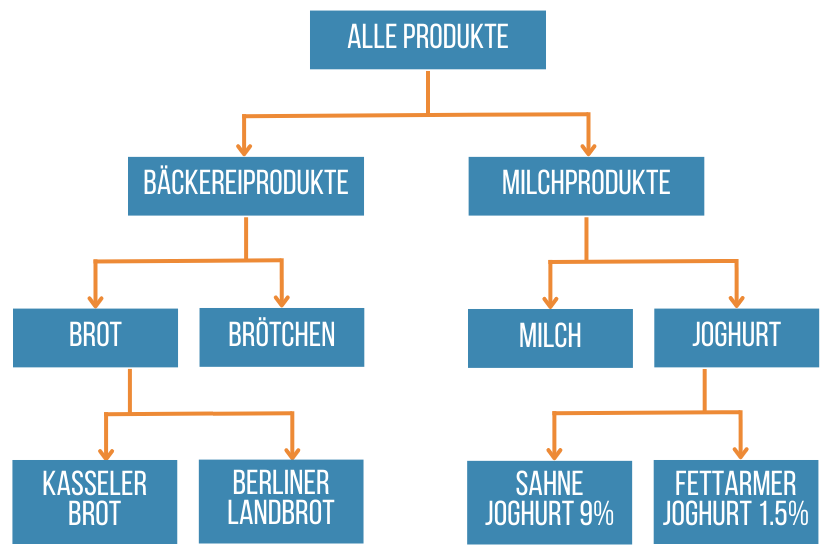
Es gibt auch einen Algorithmus zum Auffinden verallgemeinerter assoziativer Regeln, wenn es möglich ist, Verbindungen nicht nur zwischen Objekten, sondern auch zwischen Gruppen von Objekten zu finden. Wenn man zum Beispiel Informationen über die Produktgruppen hat, zu denen Objekte gehören, kann man Beziehungen finden wie "Wenn Sie Kasseler Brot gekauft haben, werden Sie auch Joghurt kaufen". Um nach verallgemeinerten assoziativen Regeln zu suchen, ist es notwendig, zusätzliche Informationen mit einem Baum von Beziehungen zwischen Objekten - Hierarchie von Gruppen in der folgenden Form - vorzubereiten:
| ID | Parent ID | Obejekt |
|---|---|---|
| 1 | Bäckereiprodukte | |
| 2 | 1 | Brot |
| 3 | 1 | Brötchen |
| 4 | 2 | Kasseler Brot |
| 5 | 2 | Berliner Landbrot |
| 6 | Milchprodukte | |
| 7 | 6 | Milch |
| 8 | 6 | Joghurt |
| 9 | 8 | Sahne Joghurt 9% |
| 10 | 8 | Fettarmer Joghurt 1.5% |
ID ist die eindeutige Nummer des Objekts. Die Parent-ID ist die Nummer des übergeordneten Objekts. Wenn es sich um ein Root-Objekt handelt, muss dieses Feld leer sein. Das Feld "Objekte" enthält sowohl Gruppen als auch Produkte.
Die Tabelle mit der Objekthierarchie entspricht dem folgenden Diagramm.
Für die Analyse von Transaktionsdaten können neben der assoziativen Regelsuche auch Algorithmen zur Identifizierung von sequenziellen Mustern eingesetzt werden, d. h. zur Identifizierung von Mustern, die besagen, dass nach Ereignis A mit einer bestimmten Wahrscheinlichkeit auch Ereignis B eintritt. Die Daten hierfür werden auf die gleiche Weise gesammelt wie für die assoziative Regelabfrage, jedoch mit dem Zusatz eines Ereigniszeitstempels.
| Transaktioncode | Datum | Produkt |
|---|---|---|
| 10200 | 2023-03-20 | Sahne Joghurt 9% |
| 10200 | 2023-03-20 | Kasseler Brot |
| 10201 | 2023-03-21 | Berliner Landbrot |
| 10201 | 2023-03-21 | Zucker, 1kg |
| 10201 | 2023-03-21 | Mineralwasser, 0,5l |
Es ist ratsam, Transaktionen in großen Datensätzen zu analysieren, da sonst statistisch unhaltbare Regeln aufgedeckt werden können. Assoziative und sequentielle Mustervergleichsalgorithmen sind in der Lage, große Datenmengen schnell zu verarbeiten. Ihr Hauptvorteil liegt gerade in ihrer Skalierbarkeit, d.h. in der Fähigkeit, große Mengen zu verarbeiten.
Das ungefähre Verhältnis zwischen der Anzahl der Objekte und dem Datenvolumen:
- 300-500 Objekte - mehr als 10 Tausend Transaktionen;
- 500-1000 Objekte - mehr als 300 Tausend Transaktionen;
Wenn die Anzahl der Transaktionen nicht ausreicht, ist es ratsam, die Anzahl der analysierten Objekte zu reduzieren, z. B. durch Gruppierung.
Modellbildung - Analyse
Es gibt eine Vielzahl von Algorithmen des maschinellen Lernens, und es würde den Rahmen dieses Artikels sprengen, sie zu beschreiben. Jeder hat seine eigenen Grenzen und löst eine bestimmte Klasse von Problemen. In der Praxis ist es meist möglich, durch die Kombination von Analysemethoden Erfolge zu erzielen.
Generell gelten die folgenden Empfehlungen zur Modellbildung, unabhängig vom Data-Mining-Algorithmus:
-
Schenken Sie der Datenbereinigung große Aufmerksamkeit. Wenn Sie die richtige Menge an Daten gesammelt haben, können Sie nicht sicher sein, dass sie von guter Qualität sind. In den meisten Fällen lassen die Daten viel zu wünschen übrig, so dass Sie sie vorverarbeiten müssen. Dafür gibt es viele Methoden: Entfernen von Rauschen, Glätten, Bearbeiten von Anomalien und so weiter.
-
Kombinieren Sie Analysetechniken. Auf diese Weise können Sie das Problem aus einem breiteren Blickwinkel betrachten. Außerdem kann die Verwendung verschiedener Methoden zur Lösung derselben Aufgabe interessante Muster aufzeigen, die über die Anwendbarkeit eines einzelnen Algorithmus hinausgehen;
-
Streben Sie keine absolute Präzision an. Es ist ratsam, mit der Anwendung zu beginnen, wenn die ersten akzeptablen Ergebnisse erzielt werden. Es ist ohnehin unmöglich, ein perfektes Modell zu erstellen. Ein brauchbares Ergebnis, auch wenn es nicht perfekt ist, ermöglicht es Ihnen, früher vom maschinellen Lernen zu profitieren. Gleichzeitig ist es möglich und notwendig, parallel zu arbeiten, um das Modell unter Berücksichtigung der in der Praxis erzielten Ergebnisse zu verbessern;
-
Beginnen Sie mit einfacheren Modellen. Mit den richtigen Daten können auch die einfachsten Modelle von Nutzen sein. Wenn mehrere Analysemethoden in etwa das gleiche Ergebnis liefern, lohnt es sich immer, die einfachste Methode zu wählen. Einfache Methoden sind zuverlässiger, stellen geringere Anforderungen an die Datenqualität und sind leichter zu interpretieren und zu ändern. Die Verwendung komplexer Algorithmen sollte durch einen ausreichenden Nutzen gerechtfertigt sein, der die höheren Kosten für ihre Konstruktion und Entwicklung rechtfertigt.
Wenn kein qualitatives Modell erstellt werden kann, gehen Sie zurück zu den vorherigen Schritten des Data-Mining-Prozesses. Leider können bei jedem Schritt Fehler gemacht werden: Die Ausgangshypothese kann nicht richtig formuliert sein, es kann Probleme bei der Erhebung der erforderlichen Daten geben usw. Darauf müssen Sie vorbereitet sein, denn Data Mining ist Forschung, d. h. die Suche nach bisher unbekannten Mustern.
Um die Angemessenheit der Ergebnisse zu beurteilen, müssen Sie Experten auf dem jeweiligen Gebiet hinzuziehen. Die Modellinterpretation sowie die Hypothesenbildung können und sollten von einem Experten durchgeführt werden, da sie ein tiefes Verständnis des Prozesses erfordern, das über die analysierten Daten hinausgeht.
Darüber hinaus gibt es formale Möglichkeiten, die Qualität des Modells zu bewerten: Testen Sie die Modelle an verschiedenen Stichproben, um ihre Verallgemeinerbarkeit zu beurteilen, d. h. ihre Fähigkeit, akzeptable Ergebnisse mit Daten zu erzielen, die dem System bei der Erstellung des Modells nicht zur Verfügung gestellt wurden.
Es gibt nämlich Analysemechanismen, die sich die ihnen vorgelegten Daten "merken" können und dabei hervorragende Ergebnisse erzielen, die aber bei Testdaten (die dem System vorher unbekannt waren) völlig ihre Verallgemeinerungsfähigkeit verlieren und sehr schlechte Ergebnisse liefern. Eine formale Bewertung kann auf der Idee beruhen, dass ein Modell, das bei Testdaten akzeptable Ergebnisse liefert, eine Daseinsberechtigung hat.
Wenn akzeptable Ergebnisse erzielt werden, müssen Sie mit der Verwendung der Modelle beginnen, aber es sollte klar sein, dass der Beginn ihrer Verwendung nicht das Ende des Data-Mining-Projekts bedeutet. Es ist immer notwendig, an der Verbesserung der Modelle zu arbeiten, denn mit der Zeit wird es notwendig sein, diesen Zyklus erneut zu durchlaufen. Außerdem stellt sich, sobald die ersten zufriedenstellenden Ergebnisse vorliegen, in der Regel die Frage nach der Verbesserung der Genauigkeit.
Die Angemessenheit des Modells für die aktuelle Situation sollte regelmäßig überprüft werden, denn selbst das erfolgreichste Modell wird mit der Zeit nicht mehr der Realität entsprechen.