Data analysis methodology
When analyzing information, it often happens that the theoretical brilliance of the analysis methods collides with reality. Everything seems to have been solved long ago, there are many well-known methods for solving analysis problems. Why do they often not work?
Because a theoretically flawless method has little to do with reality. Most often, the analyst is faced with a situation where it is difficult to make clear assumptions about the problem. The model is not known, and the only source of information for its construction is a table of experimental input-output data that contains values for input characteristics of the object and corresponding values for output characteristics in each row.
As a result, all possible heuristic or technical assumptions must be made about the choice of informative features, the class of models, and the parameters of the chosen model. The analyst makes these assumptions based on his/her experience, intuition, and understanding of the meaning of the process being analyzed.
The conclusions drawn from this approach are based on the simple but fundamental hypothesis of monotonicity of the solution space, which can be expressed as follows: "Similar input situations lead to similar output responses of the system". The idea is intuitively clear enough, and usually it is sufficient to obtain practically acceptable solutions in every case.
In this method of decision making, academic strictness is subordinated to reality. Indeed, this is nothing new. If certain solutions contradict reality, they are usually changed.
Another point is that the process of extracting knowledge from data follows the same pattern as establishing physical laws: Collecting experimental data, organizing these data into tables, and finding an argumentation scheme that, first, makes the results obvious and, second, allows the prediction of new facts.
It is clear that our knowledge of the process being analyzed, as with any physical phenomenon, is to some extent an approximation. In general, any argumentation scheme about the real world involves approximations of various kinds. The term machine learning refers to a physical approach to solving data analysis problems in addition to a mathematical one. What is meant by the term "physical approach"?
It is an approach in which the analyst examines for a process that may be too complicated to be analyzed accurately by strict mathematical methods. Nevertheless, it is possible to get a good picture of its behavior under different circumstances by approaching the problem from multiple angles, guided by expertise, experience, intuition, and using different heuristic approaches. In this way, we move from a rough model to increasingly accurate ideas about the process.
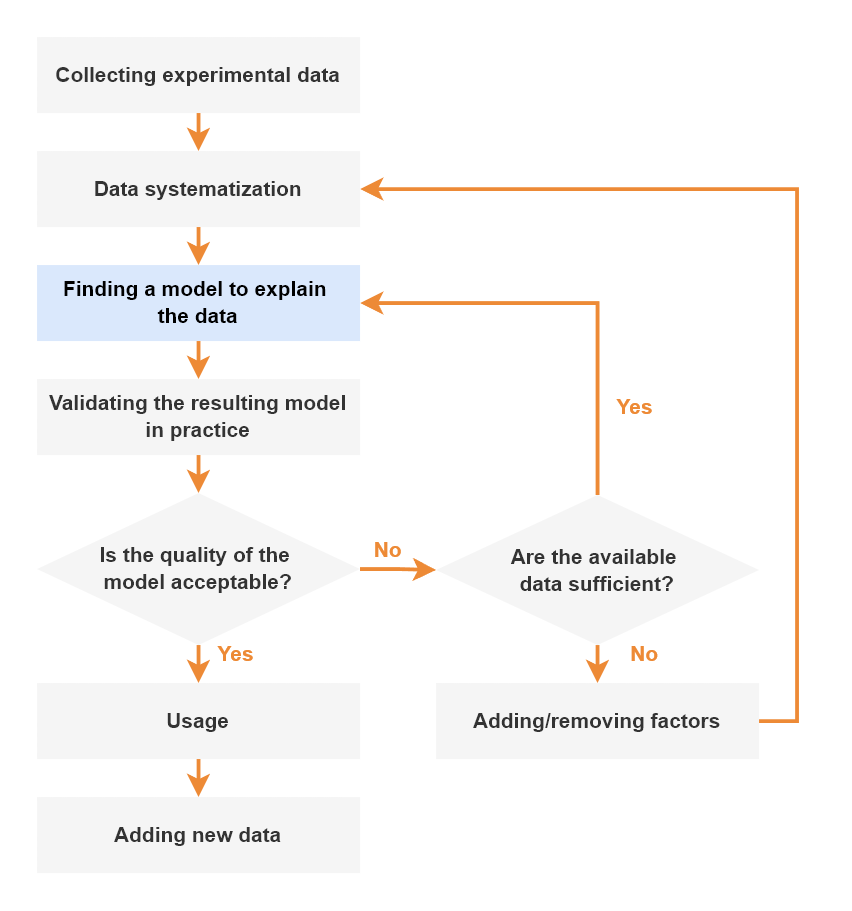
This approach implies that:
- The analysis should be based on the expert's knowledge.
- It is necessary to look at the problem from different angles and combine different approaches.
- It is not necessary to aim for high accuracy immediately, but to move from simpler and coarser models to more and more complex and precise models.
- It is worth stopping as soon as you get an acceptable result without aiming for a perfect model.
- As time passes and new information gets collected, the cycle has to be repeated - the learning process is endless.
Example
As an example, we can outline the process of analyzing the real estate market in Frankfurt. The aim is to evaluate the investment attractiveness of projects. One of the tasks to be solved is to create a pricing model for apartments in new buildings, i.e. to find a quantitative relationship between the apartment price and the price factors. For a typical apartment, these include:
- Location of the building (including infrastructure of the area; neighborhood of the building; ecology of the area).
- Location of the apartment (floor; orientation of the apartment; view from the windows)
- Type of house
- Size of the apartment
- Loggia/balcony
- Building stage (the closer to completion, the higher the price per square meter).
- Availability of equipment ("rough" equipment, partial equipment, turnkey). Most new buildings are delivered with shell work).
- Transportation accessibility (proximity to subway, ease of access, availability of parking).
- Seller (investor, developer or real estate agent).
First, from the available sales history, we can limit ourselves to the data of one Frankfurt district. The input factors are a limited number of characteristics that, from the experts' point of view, obviously influence the selling price of apartments: Design, floor, condition of the property, number of rooms, size. The output attribute is the price per square meter at which the apartment was sold. You get a fairly straightforward table with a reasonable number of input factors.
Train a neural network on this data, i.e. create a fairly rough model. The model has one major advantage: it correctly reflects the dependence of the price on the factors considered. For example, an apartment on the top floor is cheaper than a normal apartment, all other things being equal, and the price of apartments increases as the object is completed. It must then be improved and made more complete and accurate.
In the next step, the data sets of sales in other districts of Frankfurt can be added to the training set. Accordingly, features such as the distance to the subway or the ecology of the district are considered as input factors. It is also desirable to include the prices of similar apartments on the secondary market.
Professionals with experience in the real estate market have the opportunity to easily experiment and improve the model by adding or excluding factors, as the process of finding the perfect model amounts to training the neural network with different data sets. It is important to realize up front that the process is endless.
This is an example of a rather efficient approach to data analysis: the experience and intuition of a specialist in his field are used to gradually approach an increasingly accurate model of the process under study. The most important prerequisite for this is the availability of information of sufficient quality, which is not possible without a system for automating data collection and storage, something that should always be kept in mind by those who are seriously engaged in business intelligence.
Conclusion
With the described approach, real problems can be solved with acceptable quality. Of course, this technique has many disadvantages, but in reality there is no real alternative to it, unless one abandons analysis altogether. But if physicists have been using such analysis methods successfully for many centuries, why shouldn't they be used in other fields as well?